
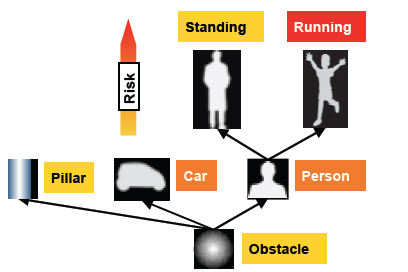
 Learning is one of the key features of intelligence: The capability of using prior experience to adapt intelligent behavior to novel situations. This requires some form of memory that may be divided into short-term and long-term memory. The stored information can be used to adapt and synthesize representations, acquire new skills and change values or preferences. This flexibility widens the scope of intelligent systems going beyond the boundaries of fully pre-programmed solutions.
Learning is one of the key features of intelligence: The capability of using prior experience to adapt intelligent behavior to novel situations. This requires some form of memory that may be divided into short-term and long-term memory. The stored information can be used to adapt and synthesize representations, acquire new skills and change values or preferences. This flexibility widens the scope of intelligent systems going beyond the boundaries of fully pre-programmed solutions.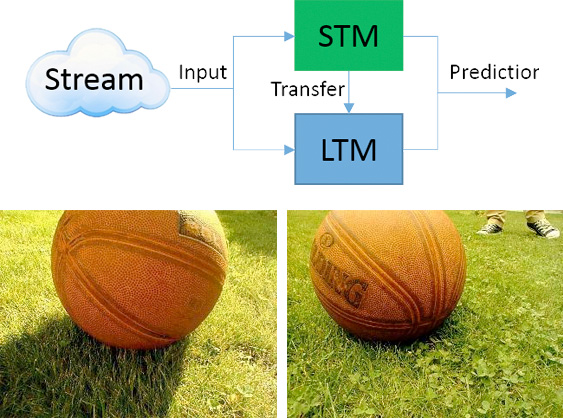 The capability to deal with change is essential, considering the fact that the world is constantly evolving. Old knowledge may become obsolete or even wrong, contradicting the current beliefs. In these dynamic conditions, algorithms clearly need to capture the current situation and then continuously adapt in order to track changes. In particular, they require a mechanism to decide whether past knowledge is still valid.
The capability to deal with change is essential, considering the fact that the world is constantly evolving. Old knowledge may become obsolete or even wrong, contradicting the current beliefs. In these dynamic conditions, algorithms clearly need to capture the current situation and then continuously adapt in order to track changes. In particular, they require a mechanism to decide whether past knowledge is still valid.

This website uses cookies so that we can provide you with the best user experience possible. Cookie information is stored in your browser and performs functions such as recognising you when you return to our website and helping our team to understand which sections of the website you find most interesting and useful.
Privacy Overview
Strictly Necessary Cookies
Show details
Strictly Necessary Cookie should be enabled at all times so that we can save your preferences for cookie settings.
If you disable this cookie, we will not be able to save your preferences. This means that every time you visit this website you will need to enable or disable cookies again.
| Name | Provider | Purpose | Expiration |
|---|---|---|---|
| moove_gdpr_popup | Honda | Storing of user's consent status for cookies on the current domain. | 7 days |
Privacy Policy
More information about our Privacy Policy